百万美元年薪,比 AI 科学家还贵,FDE 到底在做什么
2026 年,一个叫 FDE 的岗位,Principal 级别总包突破了 100 万美元。比同级别 AI 科学家高出 10% 到 25%。
美国 Indeed 平台上,FDE 岗位从 2025 年 4 月的 643 个增加到 2026 年 4 月的 5,330 个,一年涨了 729%。猎头公司 Adecco 的数据也差不多:需求增速每年约 800%,人才供给增速只有 50%。
OpenAI 和 Anthropic 在 2026 年 5 月同一天分别宣布成立企业 AI 服务公司。OpenAI 投了 40 亿美元成立 The Deployment Company(这是在致敬马斯克的”挖洞公司”吗),同时收购了一家有约 150 名 FDE 的英国公司 Tomoro;Anthropic 和 Blackstone、Goldman Sachs 合资组建 AI 服务公司。
Google Cloud 把 FDE 面试流程压缩到了 2 天 2 轮来抢人。按我之前的了解,Google 的面试流程通常是按周计算。
Perspective AI 调查了 1,200 名 FDE,78% 的受访者说团队规模将在 2027 年增长 2 倍或以上。
以下是各家公司的 FDE 总包数据(2026 年,单位美元):
| 级别 | OpenAI / Anthropic | Scale AI、Cohere 等 | Palantir | Deloitte、JPMorgan 等 |
|---|---|---|---|---|
| 中级 | 38.5万 – 66.5万 | 25万 – 45万 | ~21.5万 中位 | 19万 – 26.5万 |
| Staff | 61万 – 75万 | 40万 – 60万 | 30万 – 45万 | 26.5万 – 42万 |
| Principal | 100万 – 128万 | 60万 – 90万 | 50万 – 70万 | 35万 – 50万 |
股权占总薪酬的 60% 到 70%。Anthropic L4 FDE 每年约 44.5 万美元股权加上 27.5 万美元 base。
国内的岗位正在起步。Boss 直聘上 FDE 薪资参差不齐,上到 150k 一个月的,下到 200 块钱一天。
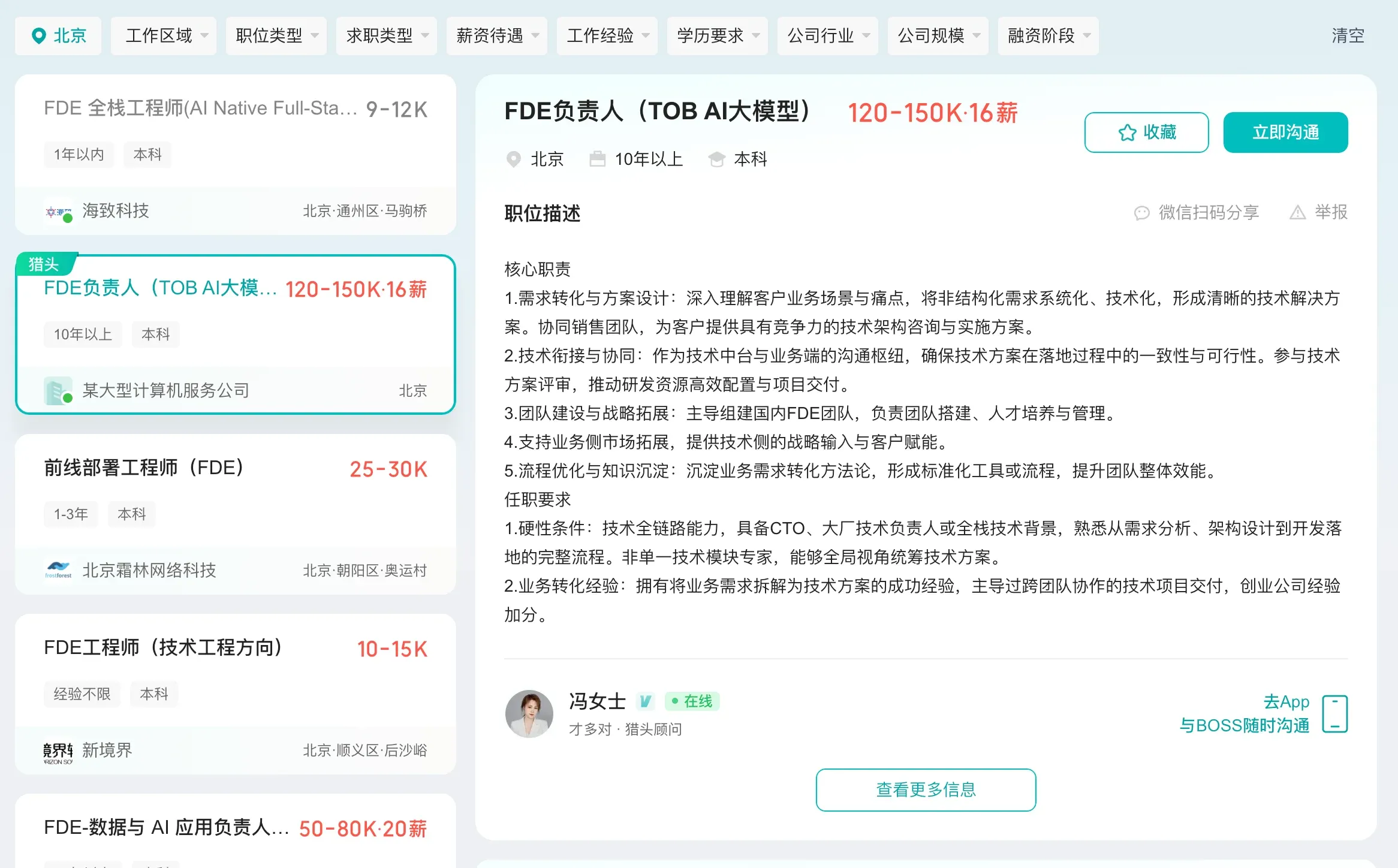
北京
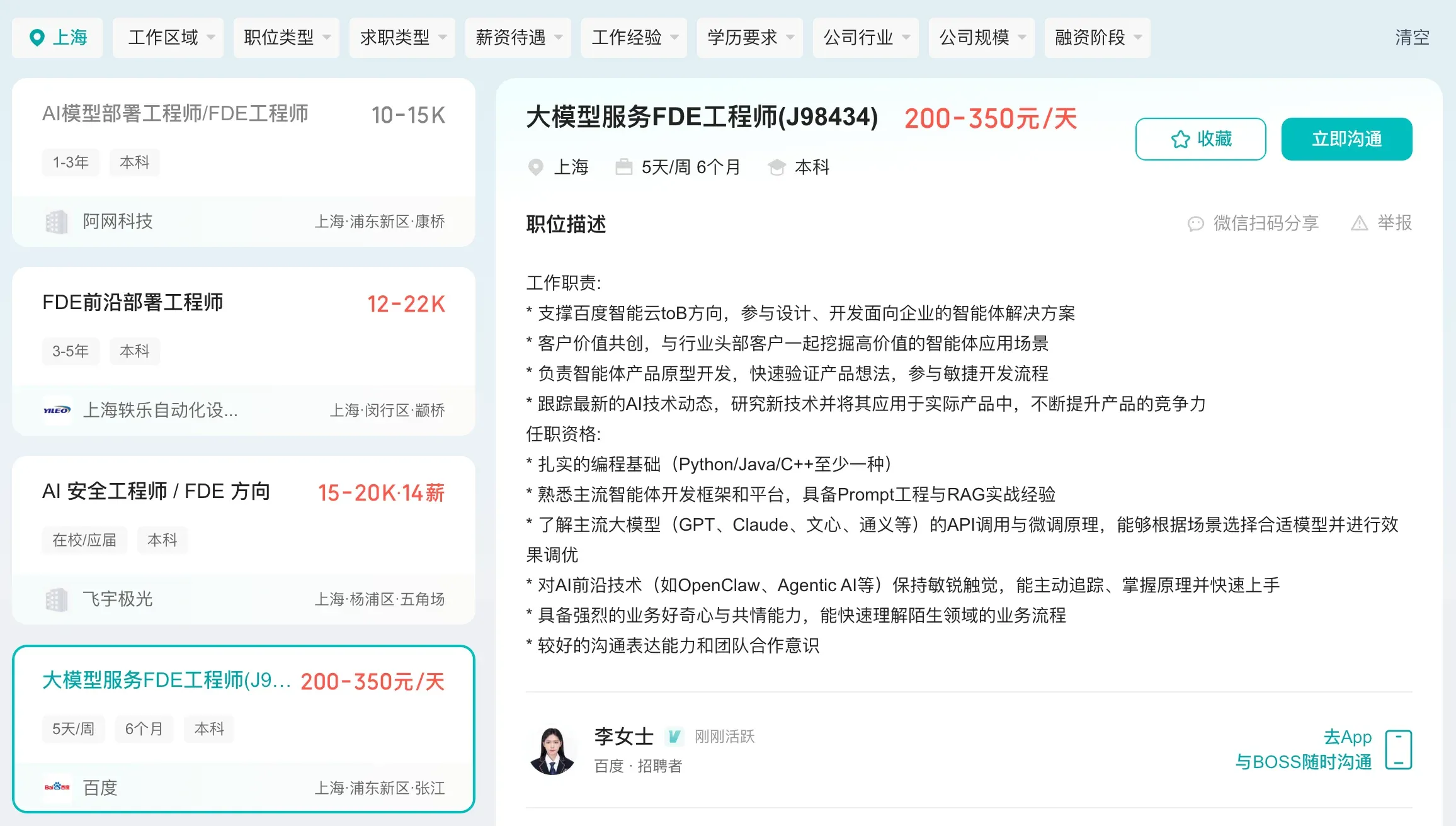
上海
”所以 FDE 到底是干什么的”
FDE 的全称是 Forward Deployed Engineer,前线部署工程师。
这个名字借自美军术语”Forward Deployed Forces”——把力量投送到离问题最近的地方。Palantir 在 2000 年代早期把这个概念引入软件行业:派工程师离开总部,长期驻场到客户现场,和客户一起工作。
Palantir 第二号工程师、后来出任 OpenAI 首席研究官的 Bob McGrew 给过一个定义:
“A forward deployed engineer is someone, typically technical and an engineer, who sits at the customer site and fills the gap between what the product does and what the customer needs.” 一个技术背景的人,坐在客户现场,填补”产品能做什么”和”客户需要什么”之间的空缺。
Palantir CTO Shyam Sankar 又总结:
“Software that works, not software that ought to work.” 交付真正起作用的软件,不是”理论上应该行”的软件。
Ok。那究竟在干嘛?
Perspective AI 对 1,500 名 FDE 的调查显示,主要是干这些事:
- 47% 跟客户聊——访谈、现场部署、设计评审
- 31% 写代码/交付
- 22% 内部协调/研究整合
写代码只占不到三分之一。调查还说,如果 FDE 整天在写代码,一般意味着某个环节出了问题。

技能上的要求,可以概括为三件:
全栈。 Python/TypeScript、React、API 设计、数据库、Docker/K8s。跟后端工程师重叠最多。
AI/Agent 实操。 LLM API、RAG、Agent 框架(LangGraph、OpenAI Agents SDK 等)。用 AI 辅助开发工具(Claude Code、Cursor)是基本要求(它们都在 JD 里)。
客户沟通和业务理解。 架构评审、高管汇报、在需求还模糊的时候已经在忙了。
这三件事单独都不新鲜,捏在一个人身上就稀缺了。能者多劳,技术越厉害人越忙。

(AI 这个图没画好,大概看下意思)
“Ok 我已经决定转型做 FDE 了,赚大钱!”
传统软件工程里,从业务需求到代码实现,翻译工作分散在几个角色之间:PM 写 PRD、BA 梳理流程、SA 做技术方案、SDE 写代码。每个角色接收的输入都比较确定,给出的输出也比较明确。这条链能工作,前提是每一段的边界清晰。
但 LLM 让自动化边界突然扩大,企业对于从需求到落地之间的时间要求也变高了。之前每个角色都能完成自己那一段,但没人能端到端地交付一个系统。每个角色都在等上一段给更明确的输入。
然后 FDE 就火了。他把 PM 的需求理解、BA 的流程梳理、SA 的技术判断、SDE 的实现能力,捏合到一个人身上。哪怕每个环节省一个人,也省了 3 个人的钱。
所以,不同背景的人转向 FDE,就得把剩下的几环补上。按起点不同,缺的东西不一样:
| 你的背景 | 你已经会的 | 你缺的 |
|---|---|---|
| PM | 需求理解、流程梳理 | LLM 能力边界、概率系统验收、48 小时原型节奏 |
| AI/ML | 模型选型、训练、评估 | 客户现场观察、风险设计、用业务语言说话 |
| SDE/后端 | 写代码、系统设计、稳定性 | 模糊需求中行动、原型加固、抽象复用 |
| MLOps | 部署、监控、数据漂移 | 客户沟通、Agent 可观测性、HITL 设计 |
| SA | 方案设计、架构评审 | 实际写代码交付、现场发现需求 |
五个角色里,SDE 和 PM 的跨越最大,也最值得展开讲。
SDE/后端工程师:从等需求到找需求
你已经会写代码、设计系统、保证稳定性。这些在 FDE 里是基本功,但不够。
第一个坎是在模糊需求里行动。FDE 接的不是 SOW(工作说明书),是 mission。客户说”帮我们提高审批效率”,进场两周发现:审批效率根本不是问题,是客户经理不知道怎么看 AI 的输出,根本不用。这时候你如果只把系统做得更快更准,项目已经死了。
第二个坎是原型的”加固”。48 小时冲出一个能看的原型,业务员说”挺好”,这只代表前 48 个小时达标了。可观测性、错误处理、边缘 case、权限、审计——把原型变成产品,是接下来几周甚至几个月的任务。生产稳定性大于一切,失去信任的系统是没人用的系统。
第三个坎是把一次定制抽象成可复用功能。FDE 不只是做项目。客户现场的共性需求要反哺到通用产品。Palantir 出来的工程师前前后后创建了 300 多家公司,不是巧合。他们在客户现场看到了足够多的”这个功能所有人都需要”。
产品经理:从写 PRD 到 48 小时出原型
你会需求理解和流程梳理。但 FDE 不做 PRD。
第一个要补的是 LLM 的能力边界。哪些需求适合用 agent,哪些用规则、SQL、普通 workflow 就够了。核心判断不是”怎么把 AI 用上去”,是”什么时候不该用 AI”。
第二个是概率性系统的验收标准。传统功能的验收条件通常是明确的(“点击按钮后 200ms 内显示结果”),agent 的输出不固定。验收就要更关注:万一错了,代价是什么,能不能撤回。
第三个是原型验证的节奏。FDE 做项目不是”需求→开发→测试→上线”,是 48 小时冲刺:进场前两天跑通一个能看的东西,给业务员看,收集反馈,第二版。第一个版本不求稳,求快。
你注意到上面一直在说要让客户用起来。FDE 不能用传统 SDE 的 KPI——代码行数、功能交付量这些一年前就已经没有意义了。FDE 的考核会说什么业务侧使用率、信任度、“从 AI 输出到业务动作的转化率”。
但实际这三个东西可以归到一个东西:客户的 AI token 用量。使用率上去了,token 用量涨;信任上去了,token 用量涨;AI 输出真的变成了业务动作,token 用量还是涨。反过来,任何一个环节出问题,token 用量最终会掉下来。
就像看一个地区的经济不用翻 GDP 报告,看用电量就行了。token 用量就是 FDE 的价值标尺。
没吃过猪肉,但我见过猪跑
上面说的这些转型要点,不是我坐在家里总结的 JD。
2022 到 2024 年,作为一个 AI 实验室的负责人,我时不时就要到客户现场待个两三周到两三个月,加上 in-house 的工作,前前后后加起来怎么也有一年。做的事和今天的 FDE 不能说很相似,只能说是一模一样。
到现场挖掘需求。客户不清楚 AI 能做什么,只知道要用起来。先把日报、周报、月报这些要收集数据、分析、生成 word/excel 的活解决了。但难点在装置上。操作间、观察流程、提出问题、把可能性翻译成可交付任务。
补领域知识。乙烯装置怎么运行、芳烃装置的关键参数、操作员的日常动作。买化工教材,找工程师要装置手册。每个行业都有自己的领域知识,FDE 不管进入什么行业都得补,否则客户没空搭理你。
数据源混乱。PI 系统的记录精度不够,控制系统的数据只有 Excel,现场记录用的是 WPS,某几个月数据丢了。先梳理出哪些数据可靠、哪些缺失、哪些口径不一致,够忙活一个月。
交付定制化系统。有传统工程(接数据、做界面、写逻辑),有 AI/ML 部分(建模、故障检测、根因分析),也有”报表一键导出”这种技术上简单但体感明显的取巧模块。
人在回路。操作员参考 AI 的建议来操作,以 shadow 模式(只观察不操作)运行一个月,是推进技巧也是基操。agent 的能力再强,背锅的永远是人。
验收标准模糊。技术深度没人懂,界面美观也没要求,结果必须可靠。但能不能达到、怎么衡量,取决于设计。让 AI 做它不擅长的事——在数据超出历史分布之外还要强行预测甚至操作——翻车是早晚的。换成预警和告警机制,把控制及时交到人手里。
没人帮你写 PRD、做技术方案评审、梳理业务流程。一个人(或者两三个人的小团队)同时做流程梳理、领域理解、数据工程、模型选型、软件开发,还有跟一屋子工艺和技术骨干开会这种很烧脑的事情。
比起两年前,现在的 AI 强太多了。以前想引入 AI 的主要是生产部门的核心装置,格式化数据多,有预算,有明确的降本增效诉求。现在大模型能读非结构化文本、理解意图、调用工具,企业想引入 AI 的范围扩大到了客服、销售、运营、人力这些部门。
但不管是以前的”AI 赋能工程师”,还是现在的 FDE,或者以后冒出来的新名字,把 AI 接到业务里要干的事和原则,变化都不大。
看完文章一个月,已经入职 FDE了!现在只想成为大佬
各大小公司还在建 FDE 的职级体系。综合多个 JD 和招聘页面:
| 级别 | 要求经验 | 重点 |
|---|---|---|
| FDE Analyst / Junior | 0–2 年 | Hire-to-train,学习全栈 + 云 + AI |
| FDE / Senior Analyst | 2–5 年 | 独立端到端部署,设计 agent 方案 |
| Senior FDE | 5–8 年 | 战略客户,影响产品路线图 |
| Staff / Principal → 管理层 | 8+ 年 | 多客户技术领导,pre-sales |
不看这些虚头巴脑的。AI 也还没 8 年,哪来 8 年经验?能力的成长比职级更有用。我把它分成四层:
第一层:能部署。 把 AI 系统在客户环境里跑通。环境适配、接口调试、权限配置。通关后你就是一个”会装工具的人”。
第二层:能诊断。 部署之后业务侧不用,你能判断为什么。是界面问题、输出格式问题、还是信任问题。把系统跑起来之后盯着业务员的实际使用,看到底卡在哪。
第三层:能设计。 从一开始就设计人机协作流程。知道哪些节点适合 AI、哪些必须留给人,在项目启动前就跟业务方画出协作流程图,给每个节点标注 AI 的角色。做到这步就可以带队了。
从第二层到第三层,关键的跃迁是建立判断框架。至少三个维度:可逆性(做错了能不能撤回)、代价分析(AI 出错了谁被考核?项目会不会直接被毙?)、信任度(业务员对 AI 的信任程度)。
第四层:能沉淀。 每次部署不只产出能跑的系统,还积累可复用的资产。部署 checklist、踩坑记录、业务侧沟通模板。下一个 FDE 拿到你的手册能少走一半弯路,你就是合格的 L4。这时候你已经是 FDE 中的战斗机了。
从第三层到第四层,关键跃迁是产品能力——从”解决一个问题”到”让一类问题从此不是问题”。

有个说法是,一流 FDE 在项目里会刻意留 10% 到 15% 的时间做记录。踩了一个坑当场记三句话,发现一个不规范的 API 当场记下来,搞定了一个难沟通的业务员当场记下发生了什么事让你终于理解了他为啥刁难你。别等项目做完了再写,那时候什么都想不起来了。
“真不错!现在就是担心别犯啥错误被开除“
送你一份”FDE 不做什么”指北:
不要在所有地方用 Agent。 能用规则用规则,能用 SQL 用 SQL,能用普通 workflow engine 就不要让 agent 自由发挥。Agent 的灵活性有代价:不可预测、难调试、出问题难定位。
不要把原型当产品交付。 48 小时冲出一个能看的原型,业务员说”不错不错”,这才是第一步。可观测性、错误处理、边缘 case、权限、审计,都需要谨小慎微。把原型当产品交付,一周之后线上出了个岔子工程师被批了,就别指望他帮你说话。前面的工作都白费了。
不要只做客户定制。 外网有人把 FDE 叫成”professional services with better branding”(起了个好听名字的外包)。如果 FDE 的工作退化到无休止的定制化实施,那真就成了高级外包。FDE 的价值在于抽象:能不能从一次定制里看出可复用的产品功能,能不能把现场发现系统化地反哺到产品路线,最后形成一套行业通用 playbook。
不要指望靠数字建立信任。 没有一个案例是只靠”准确率 99%“让业务侧接受的。业务侧怕的是那 1% 有没有东西兜底。建立信任靠双轨测试、影子模式(只观察不操作)、种子用户共建(拉积极客户合作)。让对方亲眼看到、亲身参与。信任靠设计,不靠数字。
不要过度自动化。 AI 接管太多,人的判断能力会退化。要刻意保留人的实践机会。凡是用 AI coding 写出线上 bug,或者不小心搞出一堆平台账单的人(别问我)都会理解。一年的利润和百倍的效率,可能一次就都交出去了。
这个号的主题是从 MRR 0 到 1 万刀的过程。但也会有 AI 企业培训相关的内容,本篇就是其一。
微信公众号:@金哲Dev